Our word-as-image illustrations concentrate on changing only the geometry of the letters to
convey the meaning.
We deliberately do not change color or texture and do not use embellishments.
This allows simple, concise, black-and-white designs that convey the semantics clearly.
We rely on the prior of a pretrained Stable Diffusion model to connect between text and images, and utilize
the Score Distillation Sampling approach to encourage the appearance of the letter to reflect the
provided textual concept.
Given an input word, our method is applied separately for each letter.
We represent each letter as a closed vectorized shape.
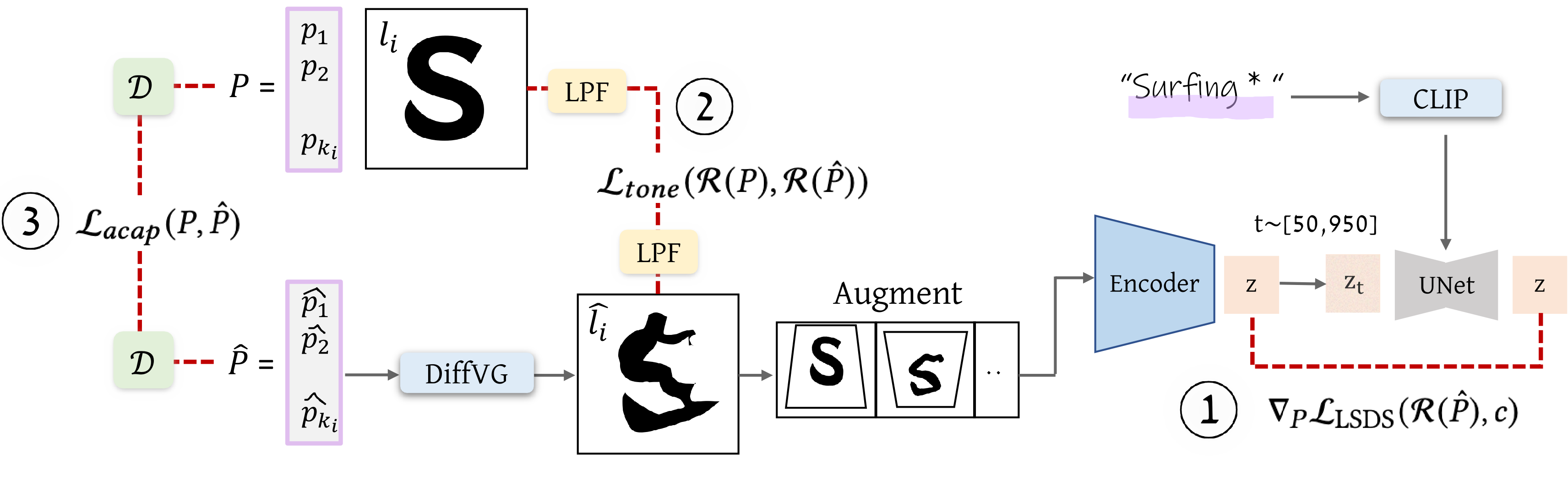
Given an input letter represented by a set of control points 𝑃, and a concept (shown in purple),
our goal is to optimize its parameters to reflect the meaning of the word, while still preserving its original style and design.
we optimize the new positions 𝑃ˆ of the deformed letter iteratively. At each iteration, we use a differentiable rasterizer (DiffVG marked in blue) that allows to backpropagate gradients from a raster-based loss to
the shape’s parameters.
We then augmented the rasterized deformed letter and passed into a pretrained frozen Stable
Diffusion model, that drives the letter shape to convey the semantic concept using the Lsds loss (1).
To preserve the shape of the original letter and ensure legibility
of the word, we utilize two additional loss functions. The first loss
preserves the local tone and structure of the
letter by comparing the low-pass filter (LPF marked in yellow) of the resulting rasterized
letter to the original one to compute L𝑡𝑜𝑛𝑒 (2).
The second loss regulates the shape modification by constraining the deformation
to be as-conformal-as-possible over a triangulation of the letter’s
shape (D marked in green), defining L𝑎𝑐𝑎𝑝 (3).
















